插画是图像处理挑战中的一个重要部分。不仅仅是由于草图比较稀疏且噪声较多,而且绘画风格还存在非常大的差异。另外,真实的使用场景要求非常精确的结果。插画研究侧重于解决这些问题,在内容创作过程中帮助插画师。
本文主要介绍两篇论文的工作。作者为日本东京早稻田大学助理教授Edgar Simo-Serra。项目获得日本科学技术振兴机构(JST,Japan Science and Technology Agency)的基金支持。
1.Sketch Simplification
论文: Learning to Simplify:Fully Convolutional Networks for Rough Sketch Cleanup
Sketch Simplification
2016年发表于计算机图形学与多媒体A类会议SIGGRAPH
摘要
本文提出了一个整体框架,用于训练一个草图简化网络,其可以将有挑战性的草图转化成清晰的线条图。笨的的方法是采用一个判别器网络来扩展一个简化网络,联合训练这两个网络,让判别器网络能够分辨出一个线条图是真实训练数据还是简化网络的输出,而反过来尝试去欺骗这个网络。该方法有两个主要优点:(2)由于这个判别器网络在线条图上学习了结构,能够鼓励简化网络的输出草图在外观上与训练草图更相似。(2)我们可以通过附加的无监督数据来训练这个网络:通过添加不相互对应的粗略草图和线条图,提升草图简化的质量,由于架构的不同,本文的方法在面对相似的对抗训练方法时在训练的稳定性和上述利用无监督训练数据的能力上表现出优势。尽管我们采用相同的结构进行推理,但是本文仍然展现了其结构在草图简化任务中训练模型的性能显著优于现有state-of-the-art方法。另外,本文提出了一个方法优化单图的性能,其利用额外的计算时间代价来提高精度。最后,本文表明采用一样的结构,可以训练网络去执行反转化问题,转化简化线条图到铅笔草图,而这是采用标准均方误差损失(standard mean squared error loss)不能做到的。
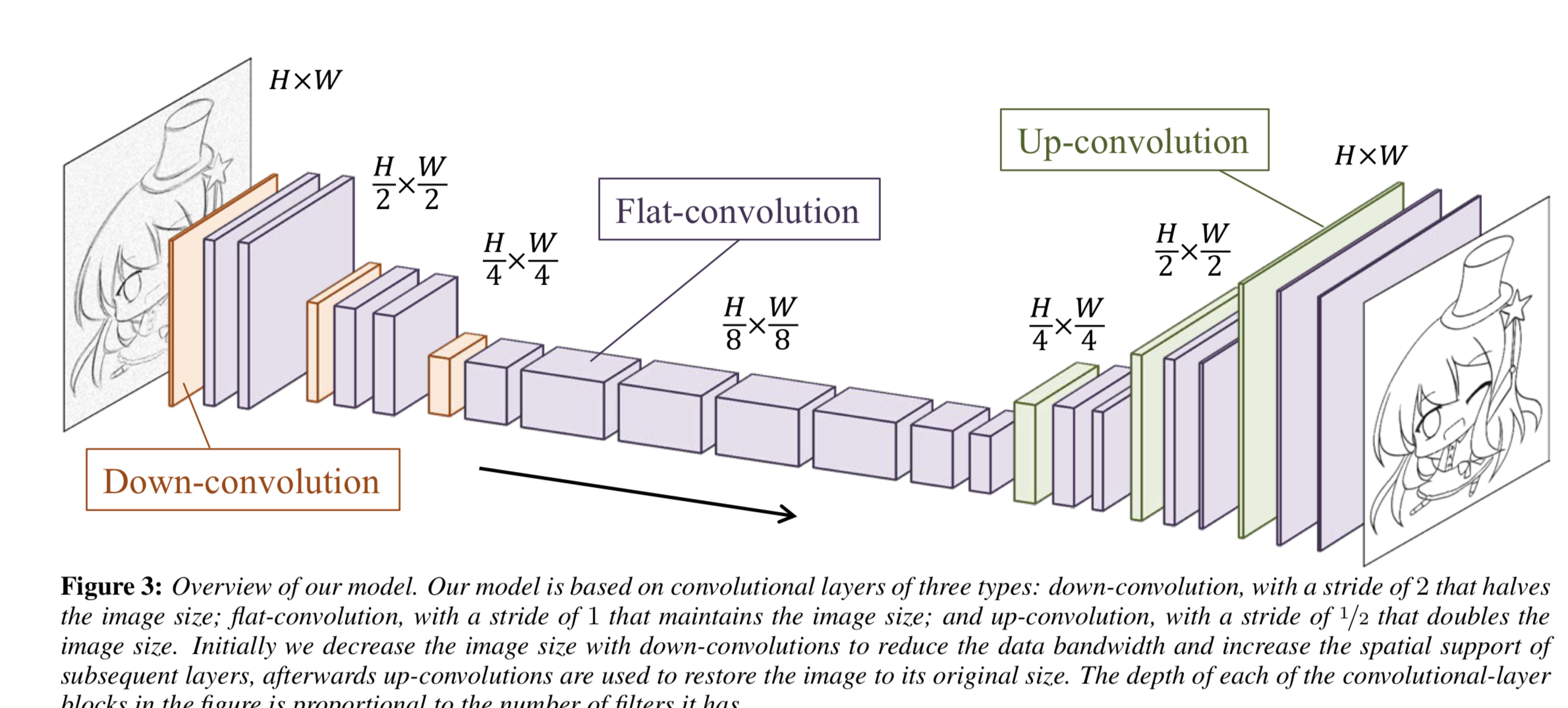
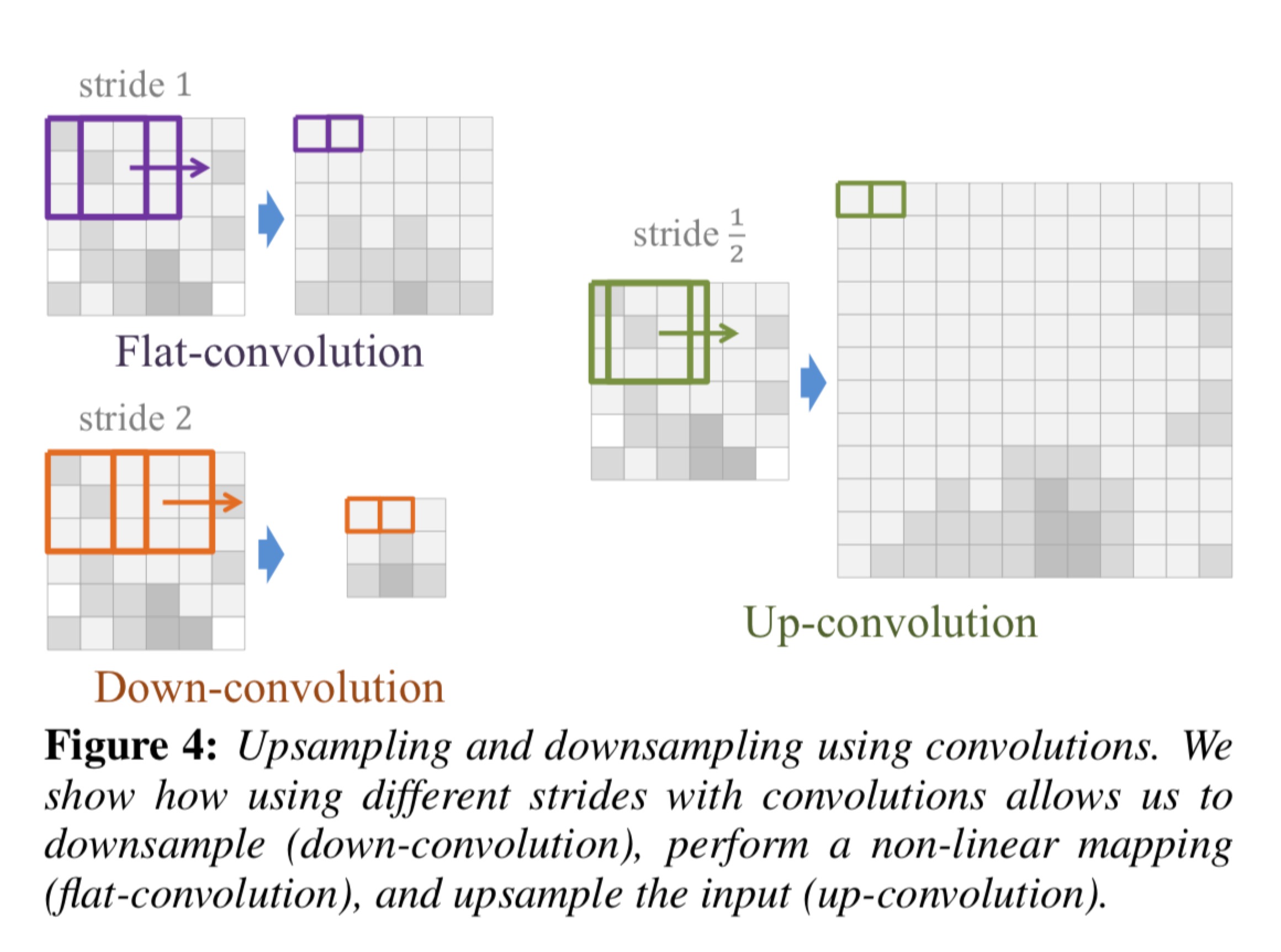
模型结构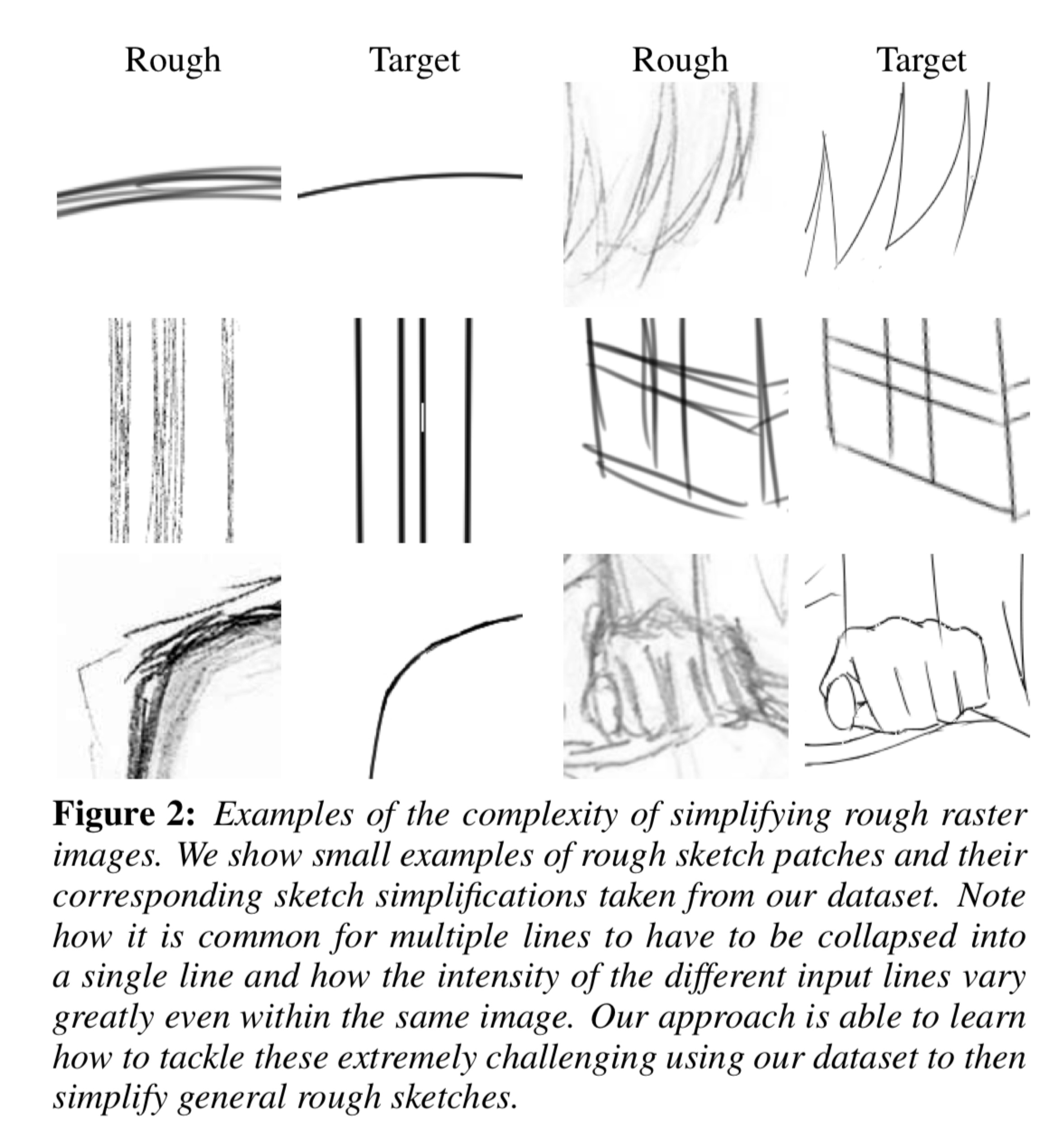
网络结构详细表
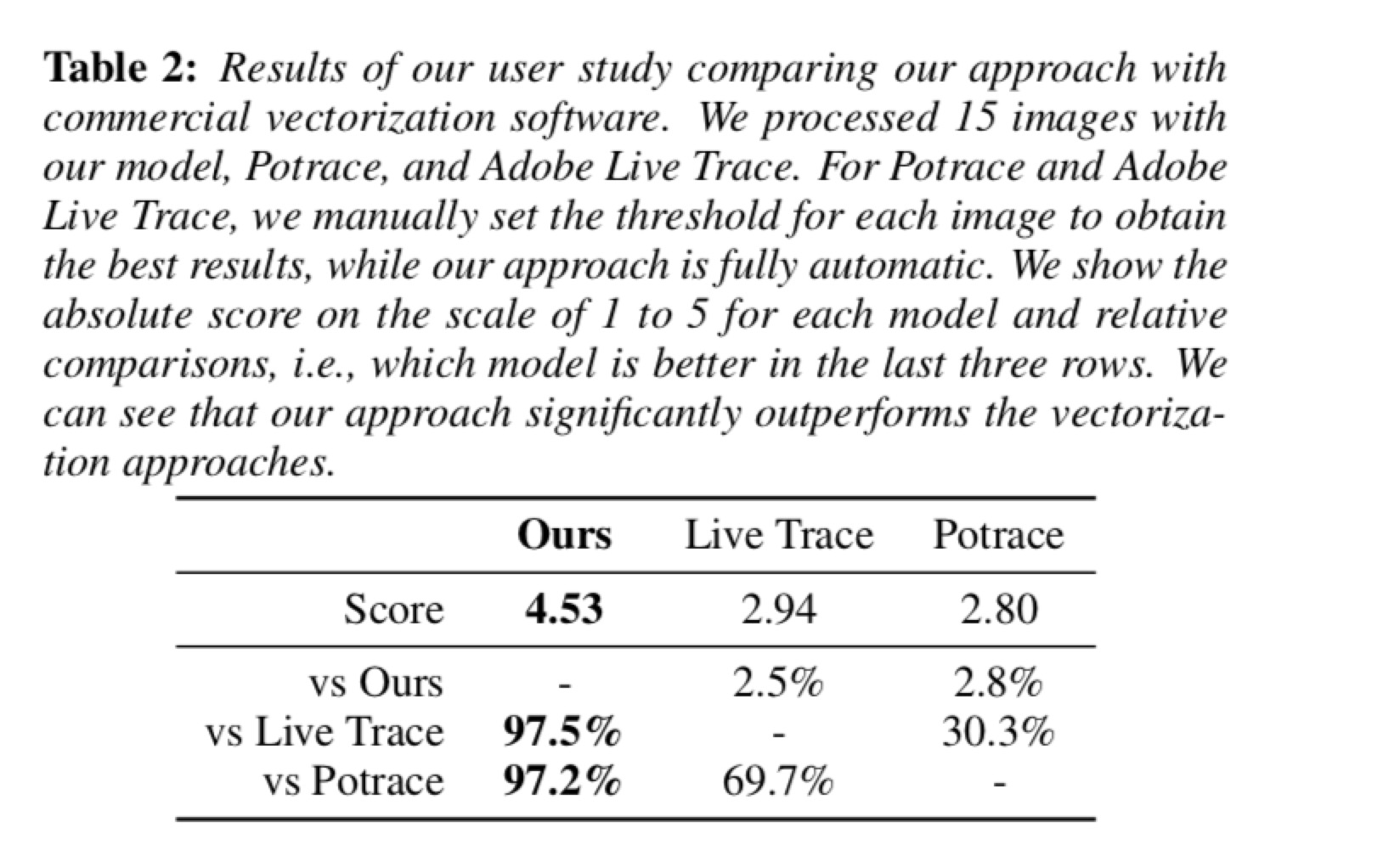
和商业应用软件进行对比
计算时间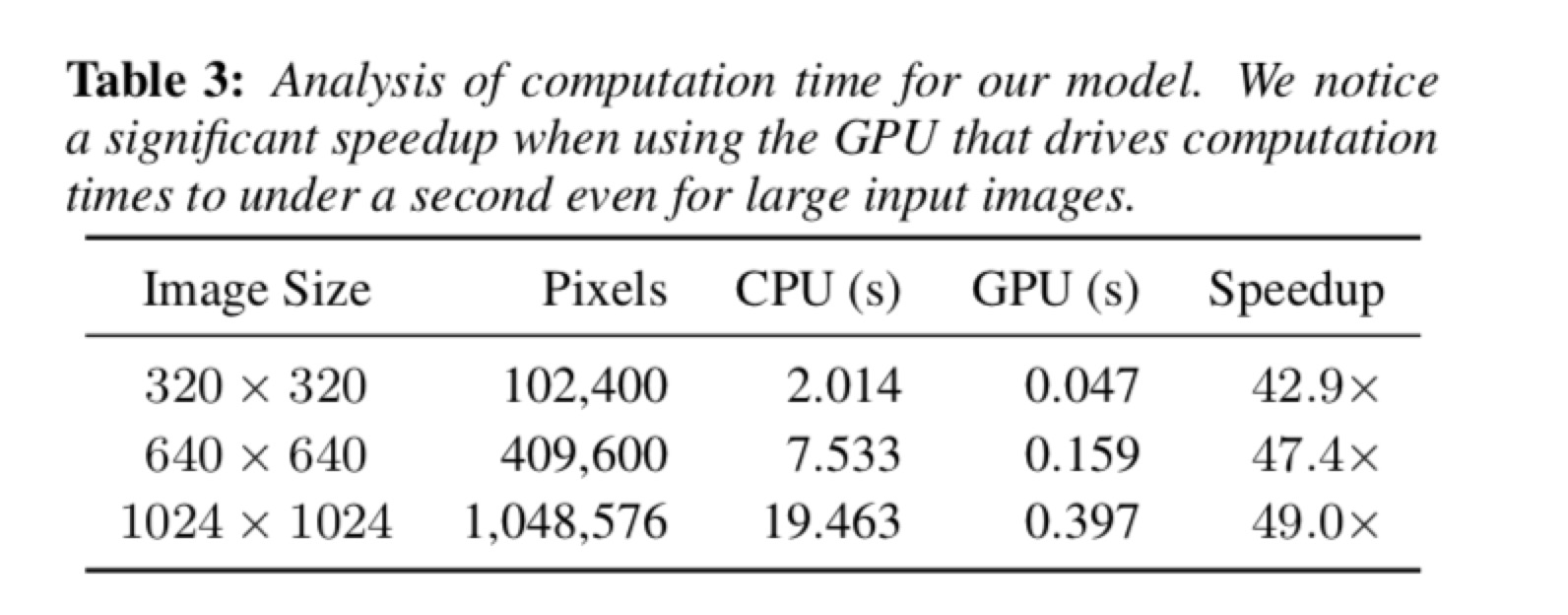
不同场景的结果
和目前state-of-the-art的方法对比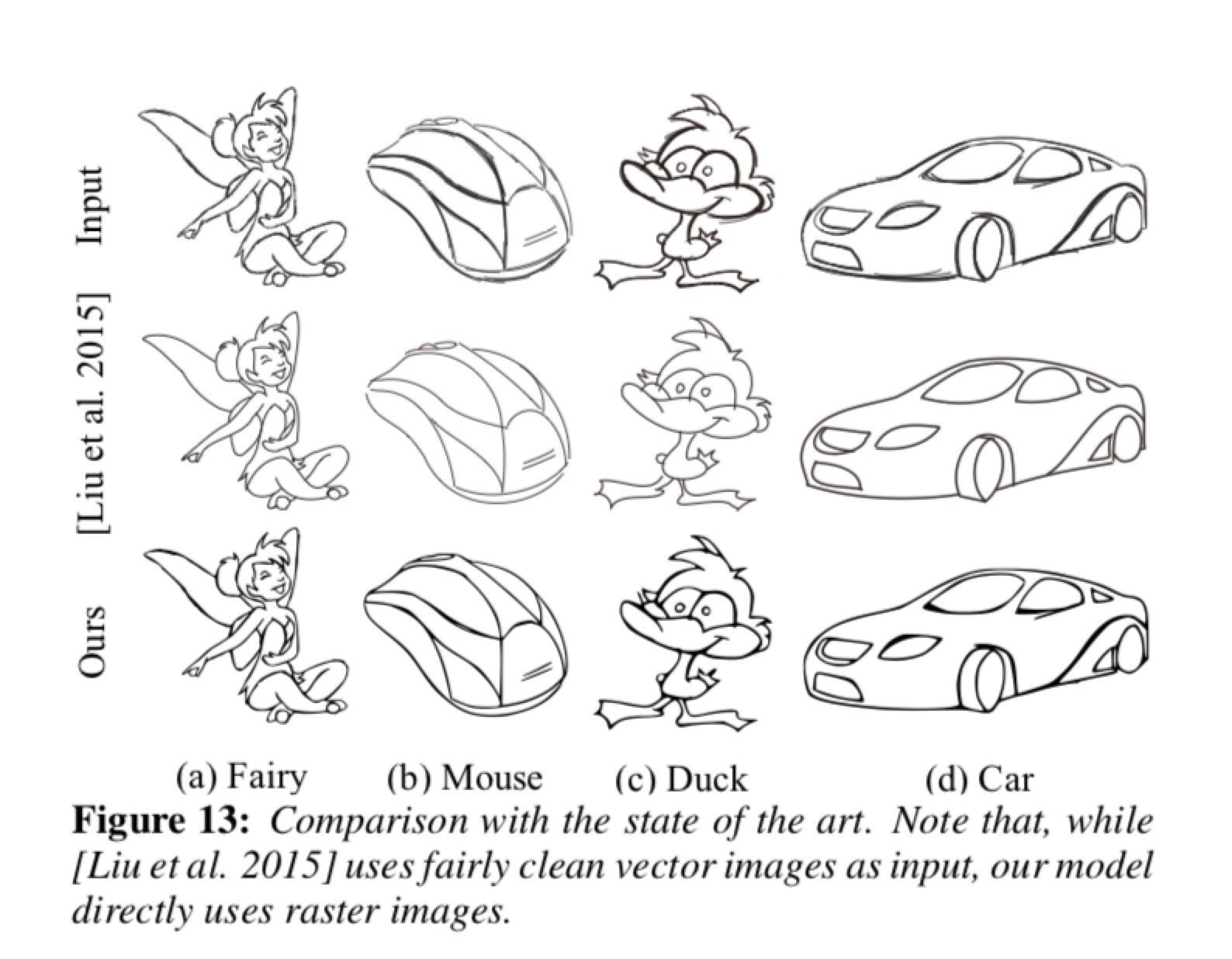
局限性
本文方法的主要局限性在于它对训练数据的质量和数量有很强的依赖性。ranger,笨的研究表明采用一个小的数据集,对于许多不同的图像仍然是能够概括的比较好的。考虑到更多的训练数据,本文的方法是能够获得更好的性能和泛化效果的。另外,虽然提出的模型推导非常快,到那时学习过程在计算上代价非常高,为了能够在合理的时间完成训练,高度依赖高端的GPUs。
总结
本文提出了一种新型的自动化端到端系统,可以获得粗糙的栅格化草图并输出高质量的矢量简化。本文的模型基于推跌卷积操作以提高效率,并且能够处理各种来源的非常具有挑战性的铅笔和纸张扫描图像。此外,本文提出的全卷积结构针对简化任务进行了优化,可以处理任何分辨率的图像。本文还针对此任务仔细设计了一个简化任务新的数据集,结合本文的学习方法,能够用来教我们的模型来简化草图。本文的方法是全自动,不需要用户干预的。研究结果表明本文的方法性能超过了目前state-of-the-art的草图简化方法,尽管没有分享在保持1s以内的计算时间只能够处理矢量图的这一严重局限性。我们还和使用者研究进行了确认,采用本文的模型能够获得比目前商业化的矢量软件获得更好的性能。本文的方法是能够将草图简化整合到艺术家日常工作流程中的重要一步。
2.Mastering Sketching
论文: Learning to Simplify:Fully Convolutional Networks for Rough Sketch Cleanup
Mastering Sketching
2017年发表于计算机图形学与多媒体A类期刊TOG
摘要
本文提出了一种新型的技术通过学习一系列的卷积算子来简化草图绘画。与目前存在的方法要求矢量图输入相反,本文允许更多更多通用的、有挑战性的粗糙栅格草图进行输入,例如通过扫描的铅笔草图获取到的栅格化草图。本文转化粗糙的草图到简化版本,然后对矢量化进行修改。这些操作全是自动化的,不涉及到用户交互。本文的模型采用全卷积神经网络,其与大多数现有的神经网络不同的是能够处理任何尺寸和宽高比作为输入的图像,并输出和输入图像有着相同维度的简化草图。为了教会我们的模型去简化,本文提出了一个新的数据集,其粗糙的和简化草图的图纸是成对的。通过有效使用我们提出的数据集并利用卷积算子,我们能够训练我们的草图简化模型。本文的方法自然克服了很多现存模型的限制,如输入矢量化图片和较长的计算时间;同时,本文展示了对于许多不同测试用例可以获得非常有意义的简化。最后,本文采用了一个用户研究验证其结构,在其中,本文的结构在性能上超过了类似的方法,并且在栅格化图像草图简化上获得了state-of-the-art的性能。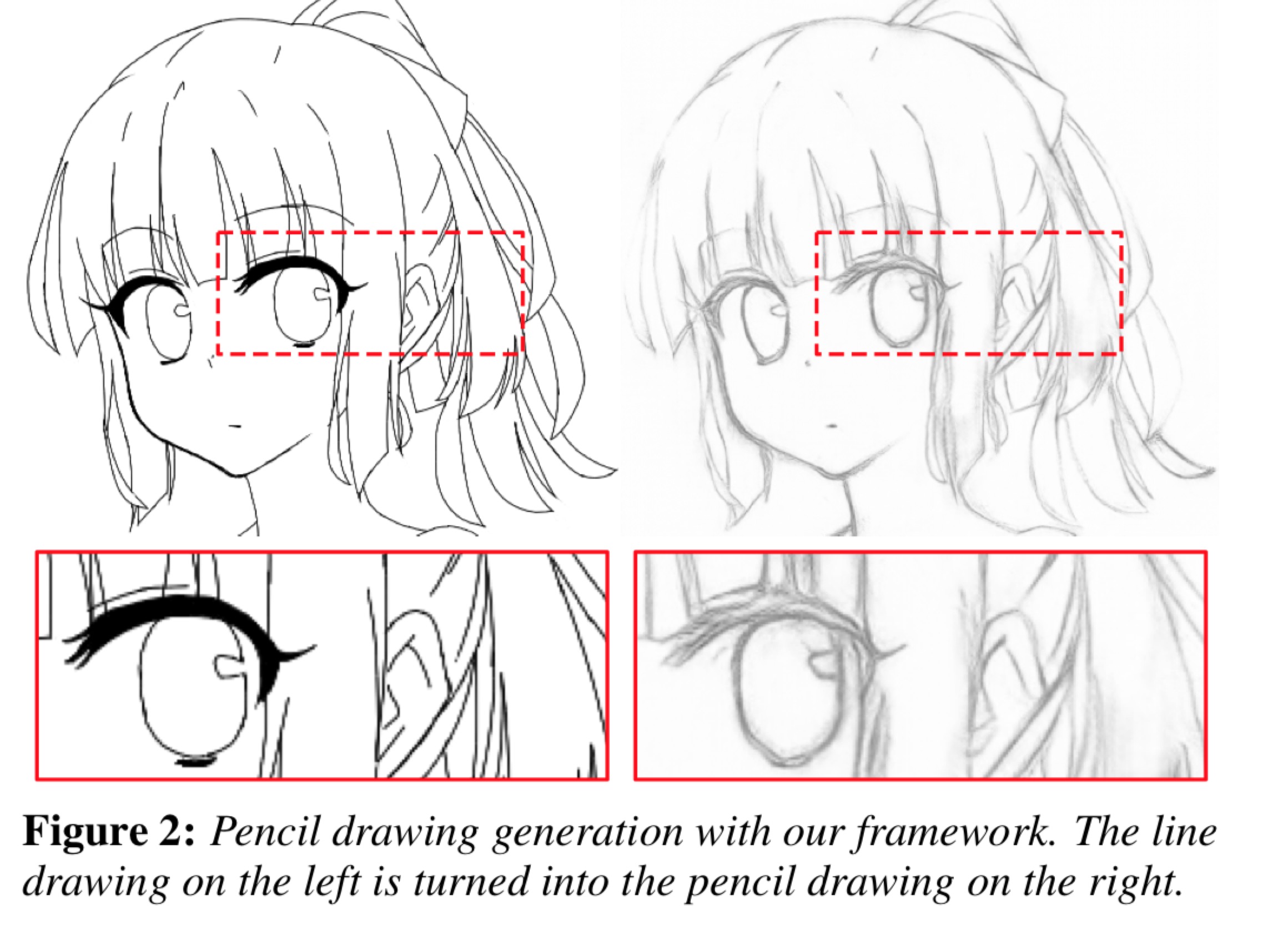
数据集介绍
本文采用方法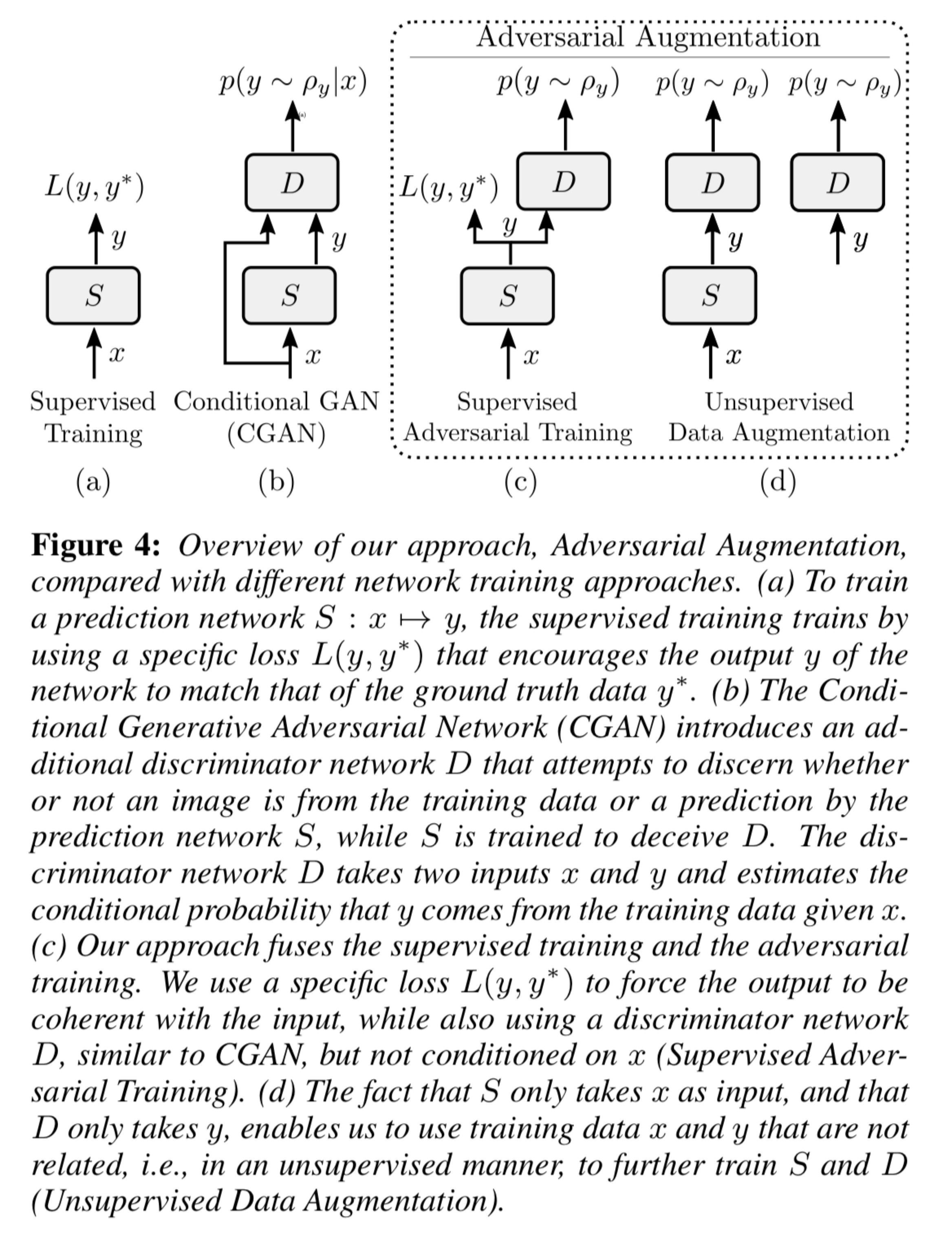
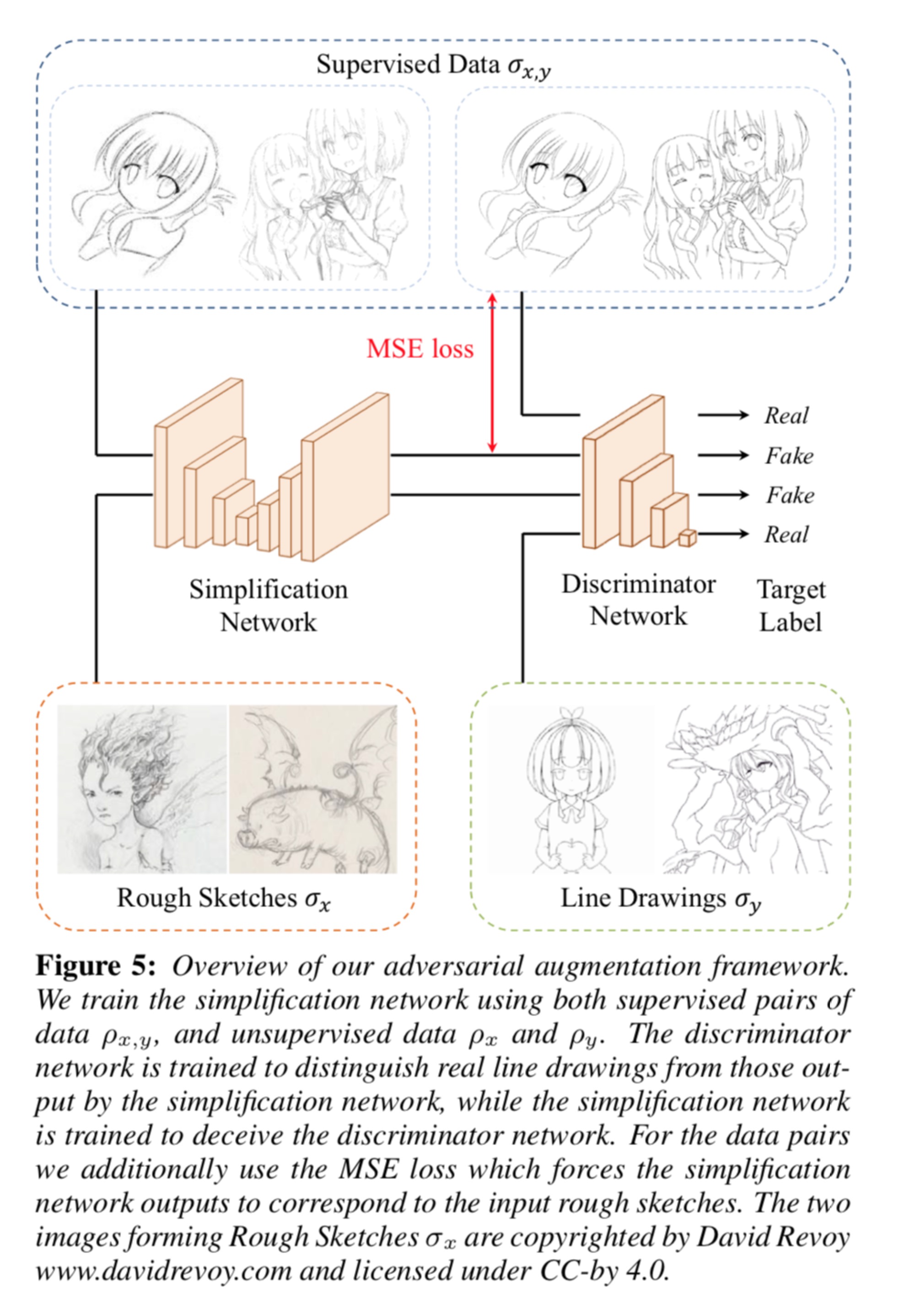
判别器网络结构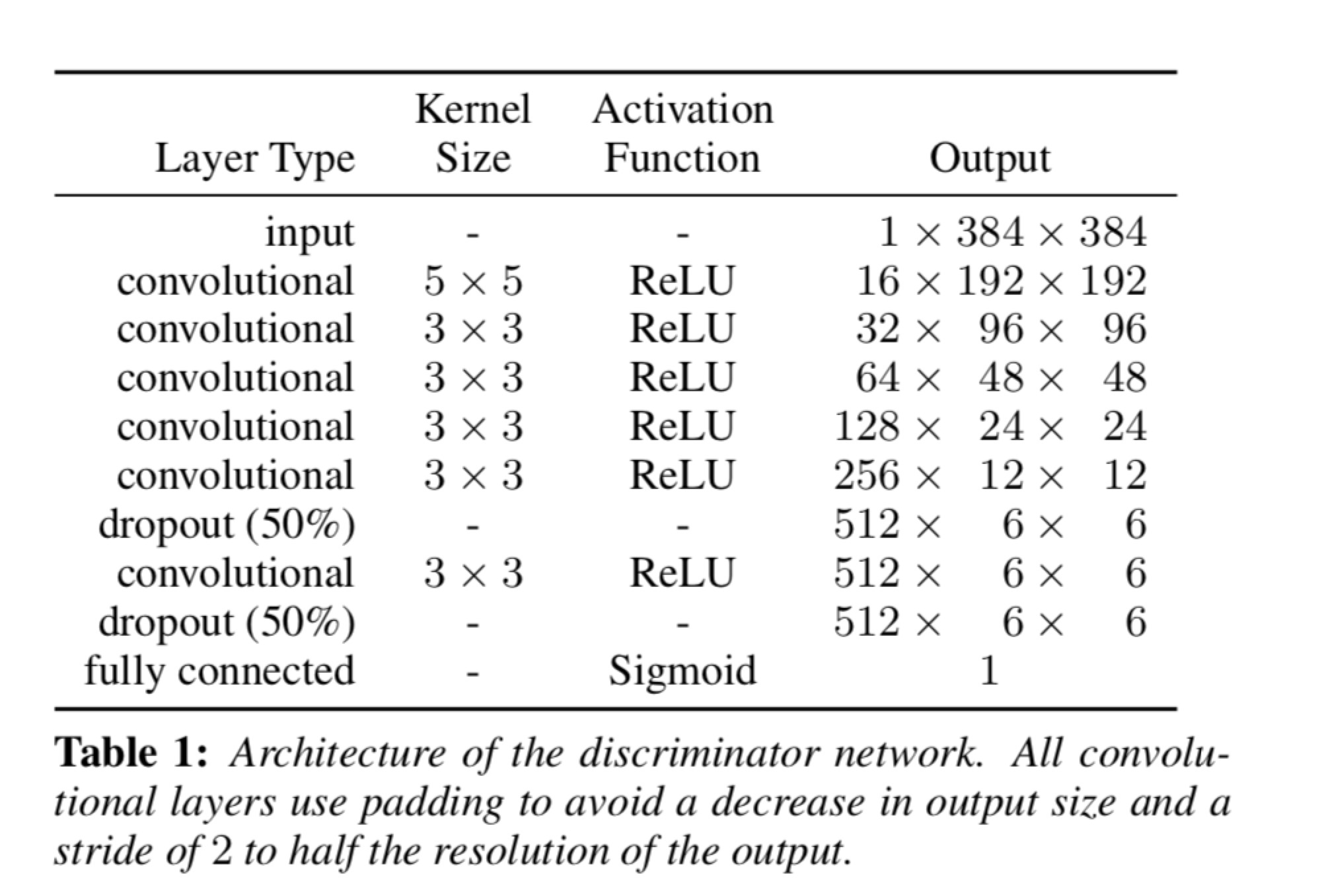
结果比较
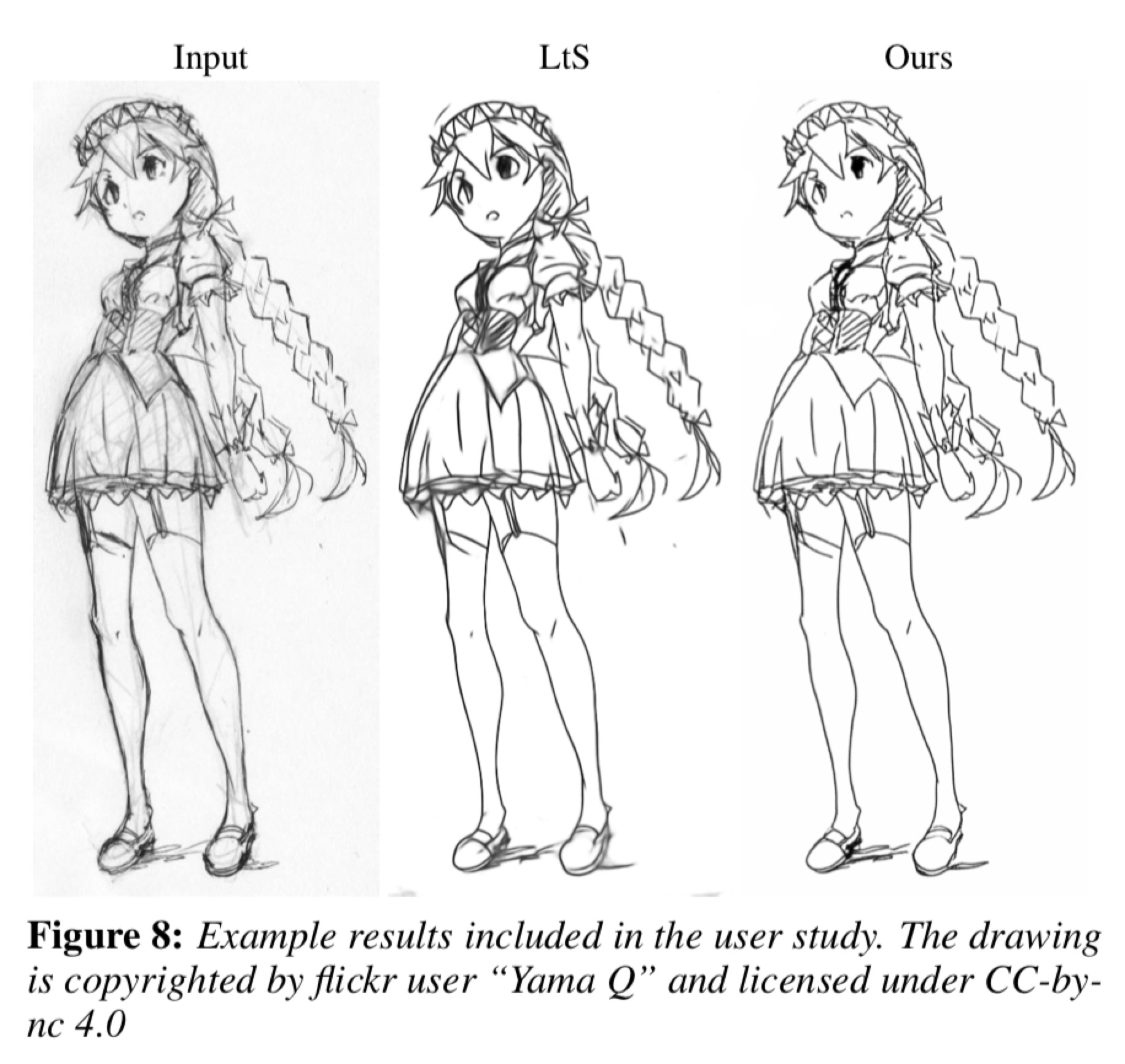
user study结果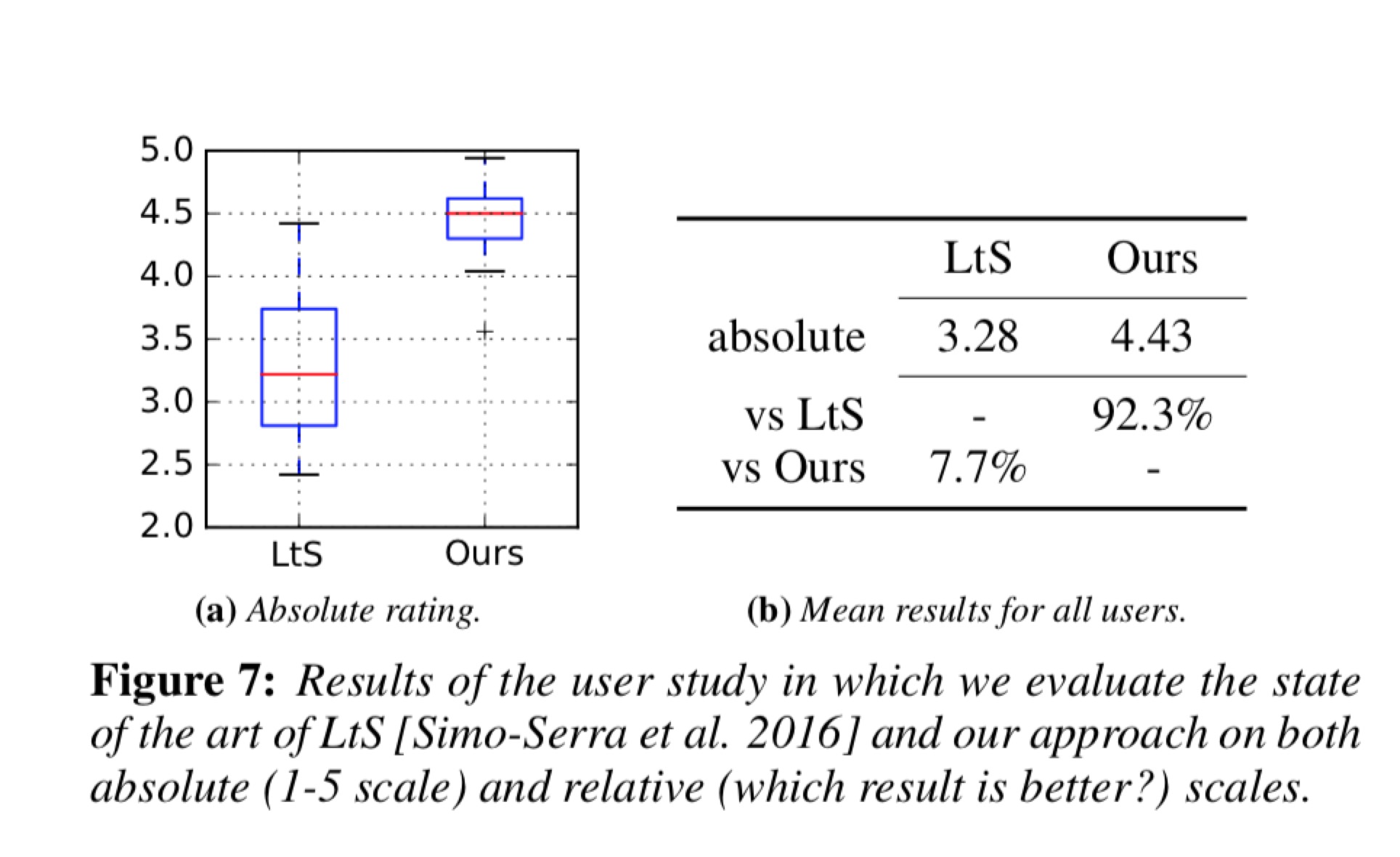




讨论
虽然我们的方法可以很好地利用无监督数据,但它依然对高质量的监督数据有着重要的依赖性,否则就不可能获得好的结果。 作为一个极端的例子,我们训练一个没有监督数据的模型,并在图14中显示结果。注意,这个模型使用LtS模型的初始权重,没有这个权重将不可能训练它。 虽然输出的图像看起来像线条图,但它们与输入的粗略草图没有任何一致性。
总结
本文介绍了针对结构预测和应用其道草图简化任务和它的逆向问题(如铅笔图的生成)的对抗增强。我们证明了通过监督对抗损失来增强标准模型的Loss,可以获得更真实的结构化输出。此外,对于结构化预测任务在获得额外的标注训练数据代价非常高的时候,允许无监督数据增强的相同结构是非常必要的。本文提出的方法已经验证了采用标准损失从清晰的草图生成铅笔图是不可能的,并且对于大多数结构化预测问题有着广泛的适用性。
3.实验
项目地址:https://github.com/bobbens/sketch_simplification
实验环境:MacBook Pro macOS 10.13.1git clone https://github.com/bobbens/sketch_simplification
该项目基于PyTorch深度学习框架。
安装依赖
这里采用的python版本是python3.6版,可以安装Anaconda,下载地址:https://www.anaconda.com/download/
下载适合自己的版本
安装PyTorch:conda install pytorch torchvision -c pytorch
这里采用的是无CUDA支持的安装,如果需要支持CUDA,需要从源码编译安装。
安装pillow依赖,pillow是PIL友好的,PIL是一个 Python Imaging Library(Python图像处理库)。conda install pillow
第一次使用之前,需要下载已经训练好的模型bash download_models.sh
执行模型测试python3 simplify.py
参数选择可以查看python3 simplify.py --help
模型包括
(1)model_mse.t7:采用MSE Loss训练的模型(SIGGRAPH 2016)
(2)model_gan.t7:采用MSE和GANLoss使用监督和无监督训练数据训练的模型(TOG2017)
图像批处理执行结果./figs.sh
结果效果图查看
